
At Pickaxe, we do the majority of our custom data science work in Python. Because all of our clients have different needs and data sets, we have a large range of data lakes and storage solutions in use. We always want to support our clients’ unique goals and add value in the best way we can.
Recently, while assessing one of our client’s needs, we realized that they would benefit from more specific projections. We decided that the best solution would be to provide custom projections, using their data, in their Snowflake environment. Because so much of our custom data work is written in Python, we wanted to find a way to use our previously-created functions to create those projections.
Snowpark is a feature that allows a user to write a User Defined Function (UDF) in Python (or another coding language), and run that code directly through Snowflake. UDFs are created based on Python code using packages like Pandas, NumPy, and scikit-learn libraries. These are the same packages we use in Conda environments.
After initially prototyping the function in VS Code using Jupyter cells #%%, we were able to add the Python code to a UDF SQL definition and generate the projections on the schedule defined with our client. This enabled us to deploy our Machine Learning (ML) code directly to snowflake as a UDF or UDTF function.
The Power of Snowpark
Snowpark API is an exciting feature for Snowflake that greatly broadens what ML engineers can do. It enables us to create UDFs and UDTFs that can be implemented in Python (or Java, or Scala), which can then be run within a Snowflake session (assuming the Snowflake warehouse is powerful enough to support them). Because these functions are created in a Python environment supporting Conda, we can make use of all the data tools we love, like Pandas, NumPy, and more.
At Pickaxe, we already have Python code that is capable of generating future projections for the data cohort sizes that our client was trying to analyze. With Snowpark, we were able to deploy our existing projection generator as a UDTF in the client’s Snowflake database. Snowpark enabled us to use our code directly inside SQL query and generate projections quickly.
However, there are challenges that need to be taken into consideration when using Snowpark. If our code is too slow or too resource-hungry, that code might break with SQL execution timeouts. It may also exhaust the Snowflake warehouse’s memory or CPU limitations. So we have to be very careful to implement efficient code – otherwise, our queries will fail.
Let us assume we have following data:
select a.country, a.type_, a.date_, a.start_cohort_size as cohort_size
from data a
where a.type_ in ('actual')
order by a.type_ asc, a.country asc, a.date_ asc;
with data as (
select country,
platform,
start_year,
start_month,
subscription_period_unit,
max(cohort_size) as start_cohort_size,
'actual' as type_,
DATE_FROM_PARTS(start_year, start_month, 1) as date_,
null as projection
from pickaxe.ltv_cohorts
where country in ('Genovia','___Wakanda','___Gilead')
and subscription_period_unit in ('Month')
and platform in ('Web')
group by country,
platform,
start_year,
start_month,
subscription_period_unit,
type_,
date_,
projection
order by country, platform, start_year, start_month asc
)
select p.country_, p.type_, p.date_, coalesce(p.start_cohort_size_,p.projection) as res
from data,
table(PICKAXE.PX_LTV_PROJECTIONS_SC(country,
platform,
start_year,
start_month,
subscription_period_unit,
start_cohort_size,
48,
CAST(0.01 AS FLOAT),
country) over (partition by country)) p
where p.type_ in ('actual')
or (p.type_='projection' and p.date_>(select max(f.date_) from data f))
order by p.type_ asc, country_ asc, date_ asc;
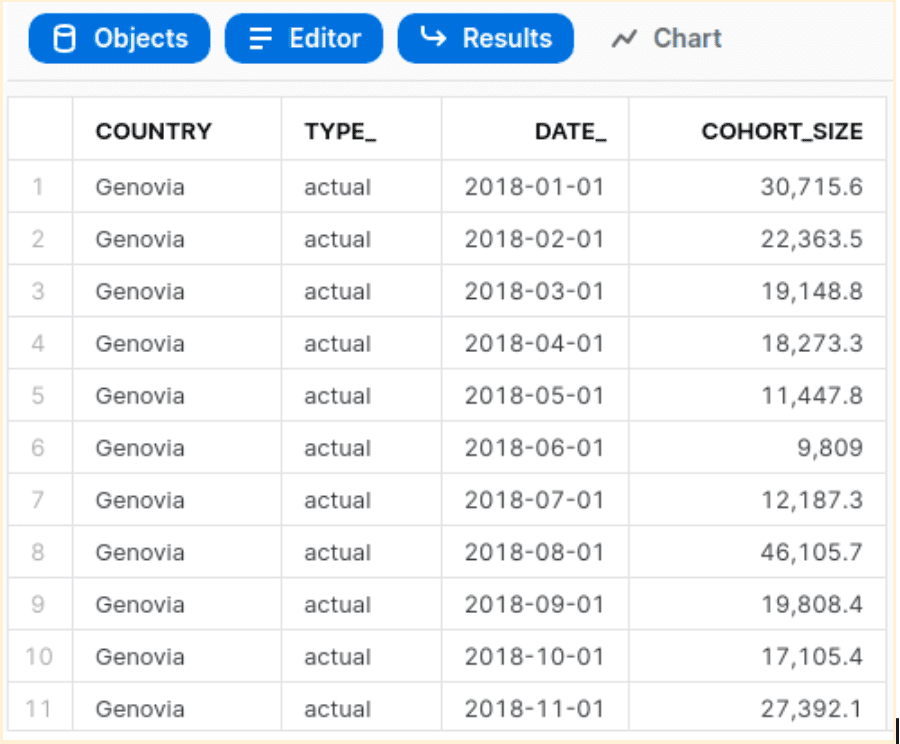
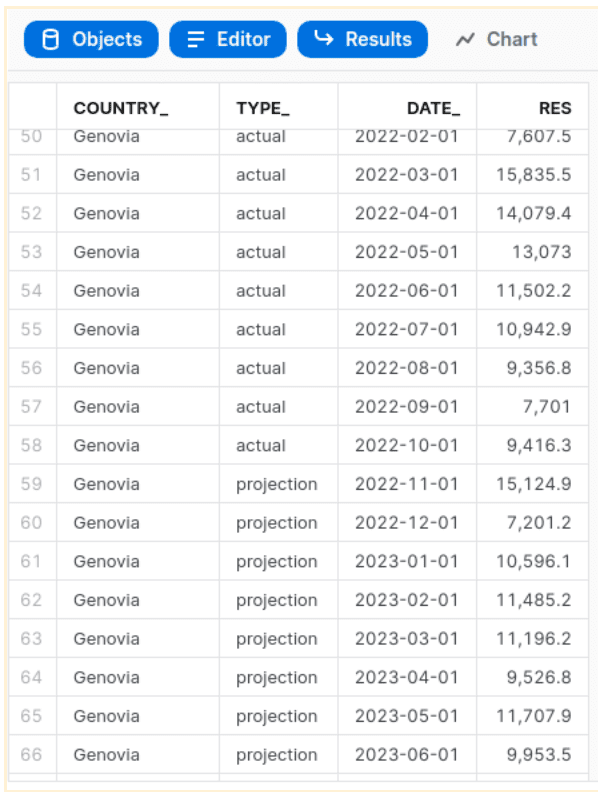
The first part of the query is returning actuals. The second part is combining actuals with projections generated by PX_LTV_PROJECTIONS_SC. The function is being executed for partitions based on country name.
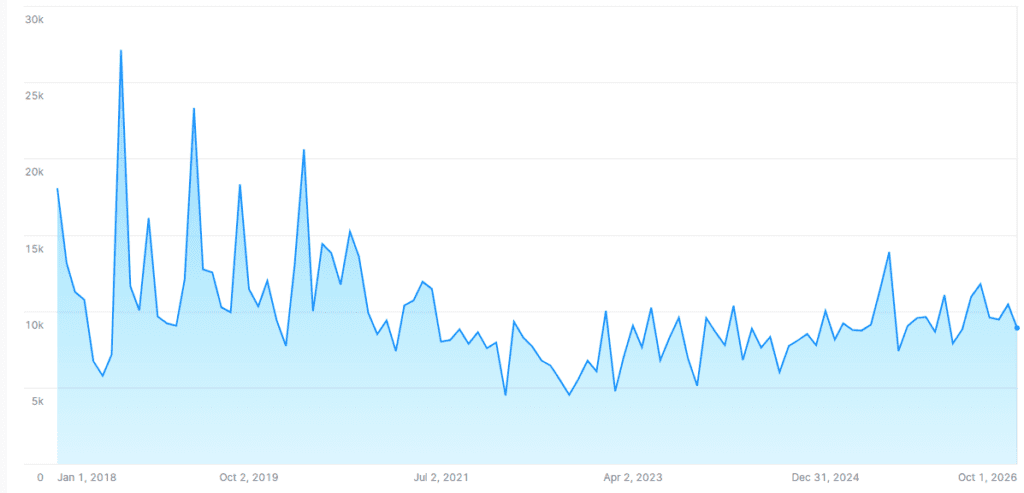
Below, you can see implementation of our Snowpark function (with sensitive information related to projections removed).
How do I create a Snowpark Function?
create or replace function pickaxe.px_ltv_projections_sc(country_ string,
platform_ string,
start_year_ number,
start_month_ number,
subscription_period_unit_ string,
start_cohort_size_ number,
num_reps number,
i_growth float,
country_name string)
returns table(country_ string,
platform_ string,
start_year_ number,
start_month_ number,
subscription_period_unit_ string,
start_cohort_size_ number,
type_ string,
date_ date,
projection number)
language python
runtime_version = 3.8
packages = ('pandas','numpy')
handler = 'X'
as $$
import pandas as pd
import numpy as np
import datetime
import math
class X:
def __init__(self):
self._date = []
self._country = []
self._platform = []
self._start_year = []
self._start_month = []
self._subscription_period_unit = []
self._start_cohort_size = []
def process(self,
country_,
platform_,
start_year_,
start_month_,
subscription_period_unit_,
start_cohort_size_,
num_reps,
i_growth,
country_name
):
self._country.append(country_)
self._platform.append(platform_)
self._start_year.append(start_year_)
self._start_month.append(start_month_)
self._subscription_period_unit.append(subscription_period_unit_)
self._start_cohort_size.append(start_cohort_size_)
self.num_reps = num_reps
self.i_growth = i_growth
self.country_name = country_name
return ((country_,
platform_,
start_year_,
start_month_,
subscription_period_unit_,
start_cohort_size_,
'actual',
datetime.datetime(start_year_, start_month_, 1).date(),
None), )
def end_partition(self):
#
..........
for row in master_df.itertuples():
aa = [self.country_name, None, None, None, None, None, 'projection']+[row[x] for x in range(len(row))]
aa[7] = aa[7].to_pydatetime().date()
tt = tuple(aa)
yield( tt )
$$;
Above, you can see our UDTF. (Lines related to projection implementation have been removed, since they don’t add much and are sensitive to our client.) However, the most important parts of the projection are still there.
Here is the declaration:
create or replace function pickaxe.px_ltv_projections_sc(country_ string,
platform_ string,
start_year_ number,
start_month_ number,
subscription_period_unit_ string,
start_cohort_size_ number,
num_reps number,
i_growth float,
country_name string)
returns table(country_ string,
platform_ string,
start_year_ number,
start_month_ number,
subscription_period_unit_ string,
start_cohort_size_ number,
type_ string,
date_ date,
projection number)
language python
runtime_version = 3.8
packages = ('pandas','numpy')
handler = 'X'
as $$
Function is going to make projections based on a query returning following columns:
with data as (
select country,
platform,
start_year,
start_month,
subscription_period_unit,
max(cohort_size) as start_cohort_size,
'actual' as type_,
DATE_FROM_PARTS(start_year, start_month, 1) as date_,
null as projection
The first part of the function’s declaration has these parameters:
country_ string,
platform_ string,
start_year_ number,
start_month_ number,
subscription_period_unit_ string,
start_cohort_size_ number,
These parameters are being used to pass actuals in the country partition boundaries. The remaining three parameters are function configuration parameters:
num_reps number,
i_growth float,
country_name string,
The ‘process’ method is collecting data for actuals and accumulating it in internal arrays. For each row of the partition column, data is being returned together with three additional columns containing row type, date and projection value. Projection value returned by ‘process’ is null, because this method is only collecting data about actuals and returning them back to the Snowflake SQL engine.
What was the key thing we learned?
We had one ‘aha’ moment related to type incompatibility. The declaration of the UDTF function is specifying the “i_growth float” parameter. It turned out that the query delivering actuals to the function has to explicitly cast the “0.01” value to the FLOAT type. For example:
PICKAXE.PX_LTV_PROJECTIONS_SC(country,
platform,
start_year,
start_month,
subscription_period_unit,
start_cohort_size,
48,
CAST(0.01 AS FLOAT),
country) over (partition by country)) p
If we don’t cast the type, the query fails like this:

We have to declare that our function will return a table with columns matching columns being returned by a query:
return ((country_,
platform_,
start_year_,
start_month_,
subscription_period_unit_,
start_cohort_size_,
'actual',
datetime.datetime(start_year_, start_month_, 1).date(),
None), )
Otherwise, we will end up with errors like this:

The second method of our handler class `def end_partition(self)` is doing a projection job. It contains our logic. We moved it from the external system into a Snowpark UDTF.
It also needs to return a table of tuples with proper size and field types:
for row in master_df.itertuples():
aa = [self.country_name, None, None, None, None, None, 'projection']+[row[x] for x in range(len(row))]
aa[7] = aa[7].to_pydatetime().date()
tt = tuple(aa)
yield( tt )
Tuple size and types have to match rows being returned by `def process`. Otherwise, we’ll end up with errors like this one:

Two extra fields were added to each tuple, to simulate tuples that don’t match with columns returned by `process`.
Key Takeaway
If you’ve written a UDTF in SQL for Snowflake, and are building UDTF implementations, then it’s important to ensure that the columns and column placeholders for the “process” and “end_partition” functions are in sync.